
U-NSGA-III¶
The algorithm is implemented based on [10]. NSGA-III selects parents randomly for mating. It has been shown that tournament selection performs better than random selection. The U stands for unified and increases NSGA-III’s performance by introducing tournament pressure.
The mating selections works as follows:

Example¶
[1]:
import numpy as np
from pymoo.algorithms.moo.nsga3 import NSGA3
from pymoo.algorithms.moo.unsga3 import UNSGA3
from pymoo.factory import get_problem
from pymoo.optimize import minimize
problem = get_problem("ackley", n_var=30)
# create the reference directions to be used for the optimization - just a single one here
ref_dirs = np.array([[1.0]])
# create the algorithm object
algorithm = UNSGA3(ref_dirs, pop_size=100)
# execute the optimization
res = minimize(problem,
algorithm,
termination=('n_gen', 150),
save_history=True,
seed=1)
print("UNSGA3: Best solution found: \nX = %s\nF = %s" % (res.X, res.F))
UNSGA3: Best solution found:
X = [-0.03361763 -0.0765763 0.08319404 -0.01884934 -0.08956898 0.02424948
-0.0742758 -0.03324263 0.01375688 0.07366408 -0.07184055 -0.03413214
0.05850567 0.00359355 0.05727249 0.08145104 0.02723058 -0.00022916
0.01453122 -0.07837368 -0.03632389 0.02878503 -0.01358104 0.00727682
-0.06518616 -0.02728898 0.01839204 0.01375858 -0.06653483 0.05340933]
F = [0.33397188]
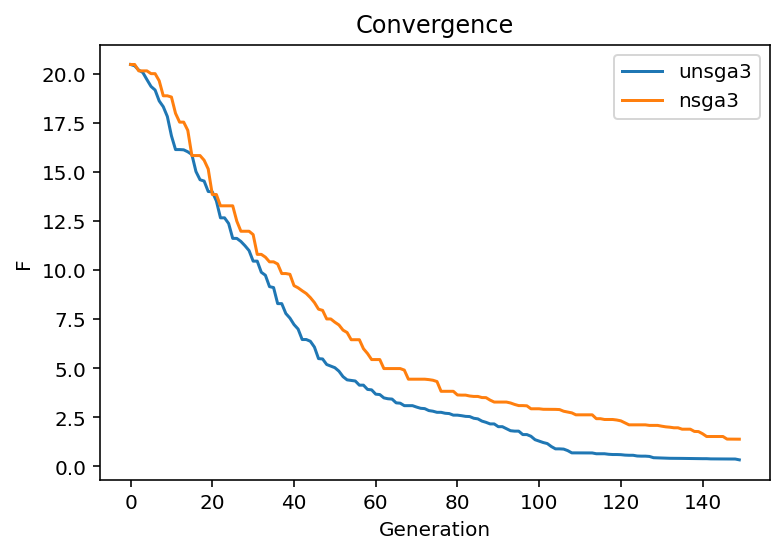
U-NSGA-III has for single- and bi-objective problems a tournament pressure which is known to be useful. In the following, we provide a quick comparison (here just one run, so not a valid experiment) to see the difference in convergence.
[2]:
_res = minimize(problem,
NSGA3(ref_dirs, pop_size=100),
termination=('n_gen', 150),
save_history=True,
seed=1)
print("NSGA3: Best solution found: \nX = %s\nF = %s" % (res.X, res.F))
NSGA3: Best solution found:
X = [-0.03361763 -0.0765763 0.08319404 -0.01884934 -0.08956898 0.02424948
-0.0742758 -0.03324263 0.01375688 0.07366408 -0.07184055 -0.03413214
0.05850567 0.00359355 0.05727249 0.08145104 0.02723058 -0.00022916
0.01453122 -0.07837368 -0.03632389 0.02878503 -0.01358104 0.00727682
-0.06518616 -0.02728898 0.01839204 0.01375858 -0.06653483 0.05340933]
F = [0.33397188]
[3]:
import numpy as np
import matplotlib.pyplot as plt
ret = [np.min(e.pop.get("F")) for e in res.history]
_ret = [np.min(e.pop.get("F")) for e in _res.history]
plt.plot(np.arange(len(ret)), ret, label="unsga3")
plt.plot(np.arange(len(_ret)), _ret, label="nsga3")
plt.title("Convergence")
plt.xlabel("Generation")
plt.ylabel("F")
plt.legend()
plt.show()
API¶
-
class
pymoo.algorithms.moo.unsga3.UNSGA3(self, ref_dirs, pop_size=None, sampling=FloatRandomSampling(), selection=TournamentSelection(func_comp=comp_by_cv_then_random), crossover=SimulatedBinaryCrossover(eta=30, prob=1.0), mutation=PolynomialMutation(eta=20, prob=None), eliminate_duplicates=True, n_offsprings=None, display=MultiObjectiveDisplay(), **kwargs) - Parameters
- ref_dirs
numpy.array The reference direction that should be used during the optimization. Each row represents a reference line and each column a variable.
- pop_sizeint (default = None)
By default the population size is set to None which means that it will be equal to the number of reference line. However, if desired this can be overwritten by providing a positive number.
- sampling
Sampling,Population,numpy.array The sampling process defines the initial set of solutions which are the starting point of the optimization algorithm. Here, you have three different options by passing
(i) A
Samplingimplementation which is an implementation of a random sampling method.(ii) A
Populationobject containing the variables to be evaluated initially OR already evaluated solutions (F needs to be set in this case).(iii) Pass a two dimensional
numpy.arraywith (n_individuals, n_var) which contains the variable space values for each individual.- selection
Selection This object defines the mating selection to be used. In an evolutionary algorithm each generation parents need to be selected to produce new offsprings using different recombination and mutation operators. Different strategies for selecting parents are possible e.g. selecting them just randomly, only in the neighborhood, using a tournament selection to introduce some selection pressure, …
- crossover
Crossover The crossover has the purpose of create offsprings during the evolution. After the mating selection the parents are passed to the crossover operator which will dependent on the implementation create a different number of offsprings.
- mutation
Mutation Some genetic algorithms rely only on the mutation operation. However, it has shown that increases the performance to perform a mutation after creating the offsprings through crossover as well. Usually the mutation operator needs to be initialized with a probability to be executed. Having a high probability of mutation will most of the time increase the diversity in the population.
- eliminate_duplicatesbool
The genetic algorithm implementation has a built in feature that eliminates duplicates after merging the parent and the offspring population. If there are duplicates with respect to the current population or in the offsprings itself they are removed and the mating process is repeated to fill up the offsprings until the desired number of unique offsprings is met.
- n_offspringsint (default: None)
Number of offspring that are created through mating. By default n_offsprings=None which sets the number of offsprings equal to the population size. By setting n_offsprings=1 a, so called, steady-state version of an algorithm can be achieved.
- ref_dirs